Установка Ceph на нодах. Инициализация мониторов. OSD. Описание текущей конфигурации кластера. Тиражирование текущей конфигурации кластера среди нод.
Установка Ceph на нодах.
Основная статья STORAGE CLUSTER QUICK START.
Обладая учётной записью ceph на каждой ноде и 4-ым пунктом Приготовления, который указал, что если используется просто имя ноды, то при использовании ssh подразумевать пользователя ceph.
Кратко команда тиражирования ceph на ноде выглядит так
ceph-deploy install {ceph-node}[{ceph-node} ...]. Подробности команды ceph-deploy install -h
Для наших 3 нод мы хотим установить релиз firefly и поэтому командуем
ceph-deploy install --release firefly ceph2 ceph3 ceph4
Инициализация мониторов.
С новой версии ceph-deploy 1.1.3 и новее, можно инициализировать мониторы и разобраться с ключами в один шаг -
ceph-deploy mon create-initial, которая зная адреса мониторов из ceph.conf сделает нужное.
Но не лишним будет знать, что до версии 1.1.3 инициализировать мониторы и забрать ключи можно было через 2 раздельных шага:
ceph-deploy mon create {ceph-node1} {ceph-node2}ceph-deploy gatherkeys {ceph-node}
Так или иначе должны появится ещё ключи в каталоге /my-cluster
ceph.client.admin.keyring
ceph.bootstrap-osd.keyring
ceph.bootstrap-mds.keyring
Добавлять в будущем ещё мониторы в существующий кластер можно с помощью
ceph-deploy mon add {ceph-node}
Командами ceph mon stat и ceph mon dump можно посмотреть текущее состояние мониторов.
OSD (object storage daemon).
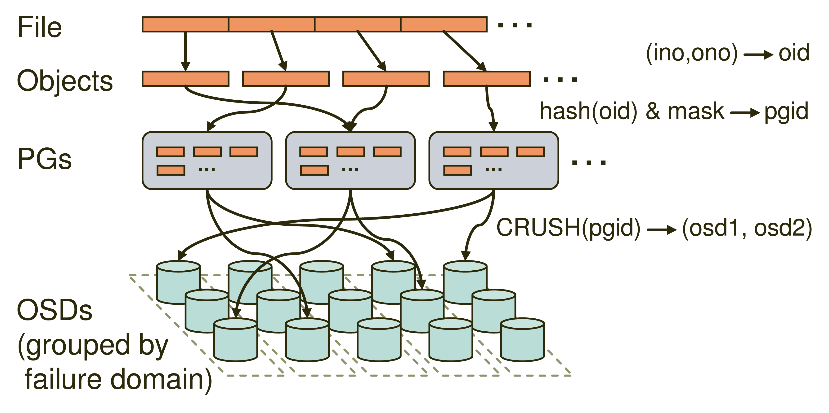
Основная статья OSD CONFIG REFERENCE.
Для хранения данных в Ceph нам для примера нужно добавить по одному диску для каждой ноды. В дальнейшем, для обучения мы добавим ещё диски, а следовательно и ещё OSD, и поучимся удалять диски, имитируя их поломки и посмотрим готовность кластера к сбоям.
Разработчики Ceph рекомендуют XFS в качестве файловой системы ваших дисков. Проверьте, что пакет xfsprogs установлен на всех нодах. Через fdisk создайте раздел на новом диске и отформатируйте его в XFS командой
sudo mkfs.xfs -i size=512 /dev/sdX
Подключите ваш новый диск в /etc/fstab, указав /mnt/disk1 как точку монтирования. У наших трёх серверов - ceph2, ceph3, ceph4 - теперь есть по одному диску и он примонтирован в /mnt/disk1. Теперь можно подготовить и активировать по одному OSD на каждый диск, который пока один.
ceph-deploy --overwrite-conf osd prepare ceph2:/mnt/disk1/ ceph-deploy --overwrite-conf osd activate ceph2:/mnt/disk1/ ceph-deploy --overwrite-conf osd prepare ceph3:/mnt/disk1/ ceph-deploy --overwrite-conf osd activate ceph3:/mnt/disk1/ ceph-deploy --overwrite-conf osd prepare ceph4:/mnt/disk1/ ceph-deploy --overwrite-conf osd activate ceph4:/mnt/disk1/
Командами ceph osd stat и ceph osd dump можно посмотреть текущее состояние OSD.
Описание текущей конфигурации кластера.
Основная статья CONFIGURING CEPH.
На данном этапе чуток задержимся и вздохнём свободно. Мы создали кластер, инициализировали мониторы и добавили на нодах по одному OSD. Теперь нужно научиться описывать нами созданное в виде конфигурационного файла, ибо ceph за нас этого делать не будет. Другими словами, все наши команды, которые мы вводили или будем вводить нужно фиксировать в виде ceph.conf.
Ceph.conf пишется в ini стиле. Есть секции:
- [global] - настройки применяться ко всем демонам Ceph.
- [osd] - настройки применяться ко всем ceph-osd демонам и перекрывают global.
- [mon] - настройки применяться ко всем ceph-mon демонам и перекрывают global.
- [mds] - настройки применяться ко всем ceph-mds демонам и перекрывают global.
- [client]- влияют на клиентов Ceph, которые используют Ceph Filesystems или монтируют Ceph Block Devices.
Если нужно что-то указать для конкретного демона, то секция пишется по традиции в числовой нотации для OSD - [osd.1]. Для мониторов Mon и MDS по традиции секции пишутся буквами - [mon.a] [mds.b].
Итак, приступим к дополнению нашего ceph.conf, который после ceph-deploy new никем не пополнялся, а мы к это времени ввели уже достаточно команд для работы кластера.
Опишем наши мониторы, пользуясь документацией MONITOR CONFIG REFERENCE и меняя IP адреса на свои. Из минимально необходимых директив это host и mon addr.
[mon]
mon clock drift allowed = 2
mon host = ceph2,ceph3,ceph4
mon addr = 192.168.200.247:6789,192.168.200.248:6789,192.168.200.243:6789
[mon.a]
host = ceph2
mon addr = 192.168.200.247:6789
[mon.b]
host = ceph3
mon addr = 192.168.200.248:6789
[mon.c]
host = ceph4
mon addr = 192.168.200.243:6789
Мониторы Ceph очень чувствительны к расхождению времени на нодах и скорее всего будет ругань от ceph. Поэтому строкой mon clock drift allowed = 2 я разрешаю разницу в 2 секунды, хотя это не замена правильно настроенной синхронизации времени между нодами кластера!
Для описания правильных секций OSD желательно вызвать команду ceph osd tree, которая выведет нам какие номера OSD каким нодам достались, когда мы делали prepare и activate. Пользуясь документацией OSD CONFIG REFERENCE пишем секции для OSD. Контролируйте, чтобы ваши секции osd совпадали с выводом ceph osd tree!
[osd]
[osd.0]
host = ceph2
osd data = /mnt/disk1/
osd journal = /mnt/disk1/journal
[osd.1]
host = ceph3
osd data = /mnt/disk1/
osd journal = /mnt/disk1/journal
[osd.2]
host = ceph4
osd data = /mnt/disk1/
osd journal = /mnt/disk1/journal
Директива osd journal указывает на расположение журнала, который разработчики Ceph рекомендуют размещать на отдельном SSD диске для бо́льшей производительности кластера, но в нашем случае журнал лежит на том же диске, что и данные. Производительности, как вы понимаете, нашему тестовому стенду это не добавляет.
Заметьте, что
osd data = /mnt/disk1/
osd journal = /mnt/disk1/journal
является общим у наших трёх нод и по логике можно было бы вынести эти две строки в секцию [osd], но в будущем мы попробуем добавить дополнительные диски разным нодам в разном количестве и поэтому я заранее описал секции osd именно так.
Тиражирование текущей конфигурации кластера среди нод.
После того, как вы вносите правки в ваш главный конфигурационный файл ceph.conf, его следует скопировать на все ваши ноды в /etc/ceph/ и себе на админскую ноду тоже! Для этого существует команда ceph-deploy admin, скомандовав
ceph-deploy --overwrite-conf admin ceph2 ceph3 ceph4 ceph1мы прикажем скопировать актуальную версию ceph.conf и нужные ключи на ноды ceph2, ceph3, ceph4. Указываем сами себя (ceph1) для того, чтобы в наш /etc/ceph/ положили ключ, который будет использоваться для доступа к кластеру, так как он по умолчанию использует авторизацию. Можете не указывать в команде
ceph-deploy admin сами себя, а просто сделать символическую ссылку /etc/ceph/ceph.client.admin.keyring -> /my-cluster/ceph.client.admin.keyring
Есть отдельная команда для копирования конфигурационного файла, не задевая ключи. Это команда
ceph-deploy --overwrite-conf config push {ceph-node}
После того, как конфигурационный файл растиражирован среди нод, следует перезапустить все ceph демоны. Воспользуемся OPERATING A CLUSTER и узнаём, что пока Debian и Ubuntu окончательно не перешли на systemd и используют систему инициализации Upstart, а следовательно рестарт службы нужно выполнить так
sudo stop ceph-all && sudo start ceph-all. Как перезапускать или останавливать отдельных демонов - читайте в документации.
По умолчанию в ceph используется авторизация между всеми демонами и параметры
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
как раз этим и занимаются.
Если у вас возникают какие-либо проблемы, то можно отключить авторизацию, выставив параметры в none
auth_cluster_required = none
auth_service_required = none
auth_client_required = none
растиражировать новый конф и рестартнуть службы.
Если всё сделано правильно:
- Время на нодах синхронизировано или укладывается в разницу mon clock drift allowed.
- Ключи и конф растиражированы правильно или параметры auth_*_required выставлены в none.
- Службы на нодах перезапущены.
То команда ceph status должна вывести что-то вроде такого:
cluster 6b74c300-2da5-43df-9c24-e7e2f9d3310a
health HEALTH_OK
monmap e1: 3 mons at {ceph2=192.168.200.247:6789/0,ceph3=192.168.200.248:6789/0,ceph4=192.168.200.243:6789/0},
election epoch 10, quorum 0,1,2 ceph4,ceph2,ceph3
osdmap e23: 3 osds: 3 up, 3 in
pgmap v43: 192 pgs, 3 pools, 0 bytes data, 0 objects
15463 MB used, 9079 MB / 24543 MB avail
192 active+clean
Кластер чувствует себя превосходно - HEALTH_OK. Три монитора в строю. Три диска в разных нодах обслуживаются тремя OSD и они в составе кластера (3 in) и работают (3 up). Active+clean подтверждает работоспособность кластера.
Назад к оглавлению.Вперёд к следующей статье.
Немає коментарів:
Дописати коментар